

如果你曾好奇成千上万段真实人声听起来是什么样的——不同的年龄、口音、语言——那么有一个数据集正好满足你。它叫做 Mozilla Common Voice,是世界上最大的开源录音语音合集之一。
来自世界各地的人们自愿朗读句子并捐献自己的录音。其成果是一个庞大的、多语言的真实语音库——任何人都可以自由使用。
只有一个问题:真正去浏览它却很难。
数据集很庞大,工具却跟不上
Common Voice 包含数百万段音频片段,覆盖数十种语言。要查看它,你通常需要下载数 GB 的数据,编写脚本来解析元数据文件,并搭建自己的播放流程。如果你是开发者,这没什么问题,但它把其他所有人都挡在了门外——研究人员、语言学家、产品团队,以及那些只想听听数据是什么样的好奇者。
我们觉得这是一个被错过的机会。
于是我们打造了 Common Voice Explorer
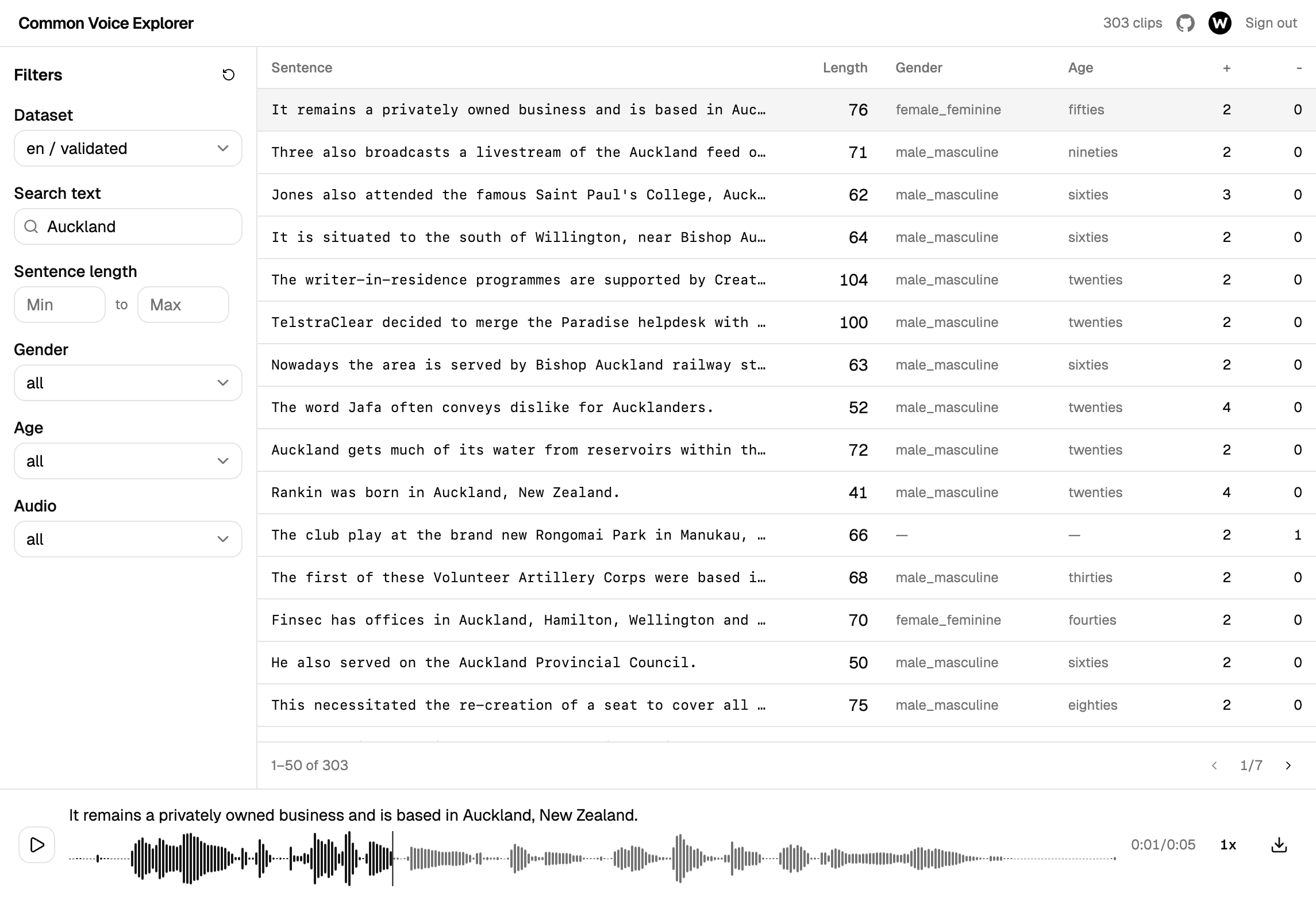
Common Voice Explorer 是一个简单的网页工具,让你直接在浏览器中浏览这个数据集。无需下载,无需脚本,无需配置。
你可以做这些事情:
- 按句子搜索 — 输入一个词或短语,立即找到包含它的片段
- 按说话人筛选 — 按性别、年龄段或语言缩小结果范围
- 按长度筛选 — 根据你的需要,查找短句子或长句子
- 即刻聆听 — 点击任意片段,伴随可视化波形聆听,调整播放速度,快进或快退
- 下载片段 — 保存单个录音以供离线审阅
它的设计就像浏览一个音乐库,只不过你浏览的不是歌曲,而是来自世界各地真实人们的真实语音。
这是给谁用的?
老实说——给任何对语音数据感到好奇的人。
- 研究人员——研究语音模式、口音或语言多样性
- 产品团队——在投入之前评估 Common Voice 是否符合自己的需求
- 语言学家和教育工作者——寻找真实的口语示例
- 语音 AI 构建者——希望快速审查数据质量
- 任何人——只是觉得听听不同的人如何说出同一个句子很有意思
你不需要懂技术就能使用它。只要你会用搜索框、会点击播放,就没问题。
这对我们为什么重要
在 WaveKat,我们正在为小型企业打造语音 AI 工具。这项工作依赖于高质量的语音数据。Common Voice 是这一领域最重要的开源资源之一,我们相信让它变得更易于访问会让所有人受益——而不仅仅是工程师。
开放数据只有在人们能真正去浏览它时才有价值。这正是我们想要填补的空白。
试试看
Common Voice Explorer 已上线,地址是 commonvoice-explorer.wavekat.com。用 GitHub 登录,接受使用条款,即可开始浏览。
如果你想先看看它的实际效果,还有一段简短的 YouTube 演示。