

如果你曾好奇成千上萬段真實人聲聽起來是什麼樣的——不同的年齡、口音、語言——那麼有一個資料集正好滿足你。它叫做 Mozilla Common Voice,是世界上最大的開源錄音語音合集之一。
來自世界各地的人們自願朗讀句子並捐獻自己的錄音。其成果是一個龐大的、多語言的真實語音庫——任何人都可以自由使用。
只有一個問題:真正去瀏覽它卻很難。
資料集很龐大,工具卻跟不上
Common Voice 包含數百萬段音訊片段,涵蓋數十種語言。要查看它,你通常需要下載數 GB 的資料,撰寫指令稿來解析中繼資料檔案,並架設自己的播放流程。如果你是開發者,這沒什麼問題,但它把其他所有人都擋在了門外——研究人員、語言學家、產品團隊,以及那些只想聽聽資料是什麼樣的好奇者。
我們覺得這是一個被錯過的機會。
於是我們打造了 Common Voice Explorer
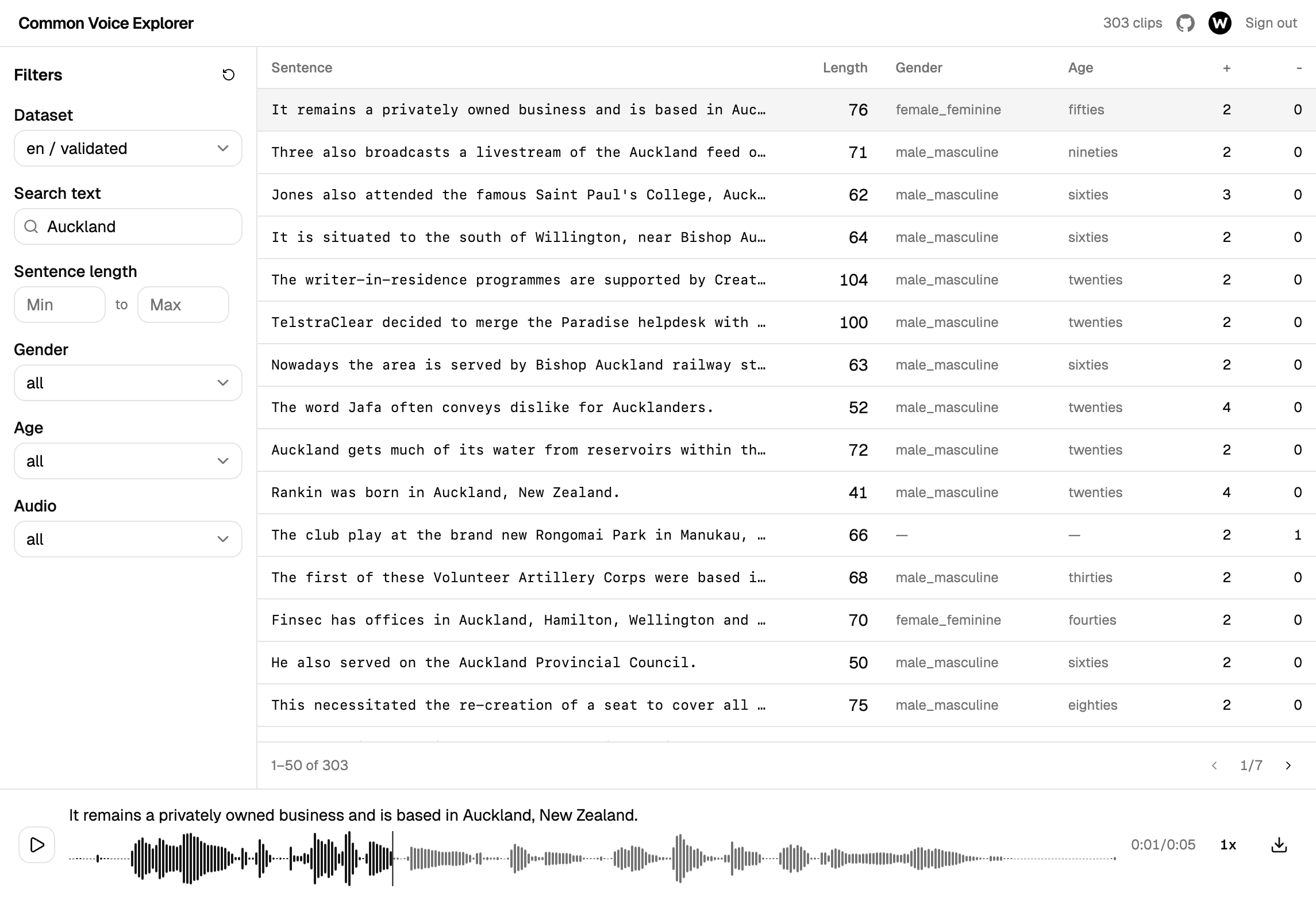
Common Voice Explorer 是一個簡單的網頁工具,讓你直接在瀏覽器中瀏覽這個資料集。無需下載,無需指令稿,無需設定。
你可以做這些事情:
- 依句子搜尋 — 輸入一個詞或片語,立即找到包含它的片段
- 依說話人篩選 — 依性別、年齡層或語言縮小結果範圍
- 依長度篩選 — 根據你的需要,查找短句子或長句子
- 即刻聆聽 — 點擊任意片段,伴隨視覺化波形聆聽,調整播放速度,快轉或倒退
- 下載片段 — 儲存單一錄音以供離線審閱
它的設計就像瀏覽一個音樂庫,只不過你瀏覽的不是歌曲,而是來自世界各地真實人們的真實語音。
這是給誰用的?
老實說——給任何對語音資料感到好奇的人。
- 研究人員——研究語音模式、口音或語言多樣性
- 產品團隊——在投入之前評估 Common Voice 是否符合自己的需求
- 語言學家和教育工作者——尋找真實的口語範例
- 語音 AI 打造者——希望快速稽核資料品質
- 任何人——只是覺得聽聽不同的人如何說出同一個句子很有意思
你不需要懂技術就能使用它。只要你會用搜尋框、會點擊播放,就沒問題。
這對我們為什麼重要
在 WaveKat,我們正在為小型企業打造語音 AI 工具。這項工作仰賴於高品質的語音資料。Common Voice 是這一領域最重要的開源資源之一,我們相信讓它變得更易於存取會讓所有人受益——而不僅僅是工程師。
開放資料只有在人們能真正去瀏覽它時才有價值。這正是我們想要填補的空白。
試試看
Common Voice Explorer 已上線,網址是 commonvoice-explorer.wavekat.com。用 GitHub 登入,接受使用條款,即可開始瀏覽。
如果你想先看看它的實際效果,還有一段簡短的 YouTube 示範。